# 一次小并发的上线复盘
由于有的人喜欢说高并发,百万并发,所以这个2万并发的项目就叫小并发吧。
# 开发阶段
之前给客户A做过一个活动,当时说活动会有1万并发,我们做了大量的优化和准备,结果上线后并发只有2千多,这个数据让我们觉得客户A喜欢吹牛。
几个月后客户A又找过来,说要做一个新的活动,称这个活动会有2万的并发。由于之前的"经验",我们觉得顶多也就3千多吧,于是开发时就比较放飞。比如核心字段用TEXT,取全表数据来排名,用了大量的MySQL等等,这些设计给后面的上线埋下了小地雷。
在上线前做了几次压测,压测目标2万,结果也还行,错误率0.04%,大家觉得OK了,没问题,上线吧。但这里压测的是开发单独给的版本,和正式版相比少了一些SQL操作,这里也是一个小地雷。
# 上线当天
上线后客户A开始推活动,开始的几分钟还正常,活动能正常进入,礼品可以正常结算。但过了几分钟后,页面开始白屏,接口一直是pending状态,客户问到:"不是说性能没问题吗,怎么都进不去了,我的推广浪费啦"。场面开始尴尬,测试开始沉默,开发开始沉默,运维开始沉默,场面开始沉默,空气非常安静。
# 找瓶颈
沉默只是再别的康桥,不是解决问题的法宝。客户的活动还要继续,怎么办?撸起袖子开始优化吧。
先看一下整个活动的流量走向。
南北流量:
用户 -> SLB -> K8S Ingress -> K8S SVC -> K8S node 应用
东西流量:
K8S node 应用 -> Redis
K8S node 应用 -> MySQL
K8S node 应用 -> 第三方接口
整个架构很单纯,看下链条中的各个节点的性能吧,找出有瓶颈节点。
通过看监控数据,发现MySQL和Redis都有瓶颈,它们的CPU都到了100%,其他都正常。
# 开始优化
# MySQL优化
1.升级配置
将MySQL迁移到了PolarDB上,由单点转为集群,硬件配置上也做了提升。这里的策略是先选个高配的,看能否顶住,之后再往下降配置,最终找到一个合适的配置。
2.找出慢SQL,优化SQL
直接看慢SQL查询即可,发现了几个问题:
1.排行榜用了全表扫描,改为用redis有序集做排行榜。
2.有些SQL用了系统函数,比如DATE函数,全部去掉,改为用node计算(此次后端用node写的)。
3.有些地方没加索引,对应加上。
4.有的地方没做类型判断,会触发MySQL的隐形转换,比如查电话号码,应该是 phone = '13412341234' , 而不是 phone = 13412341234
3.减少同步写的操作,能改为异步的就异步
比如发礼物,可以直接改为用队列来做,将同步改为异步。
# redis优化
1.升级配置
将Redis升级为集群版。
2.找出慢的redis查询
查看日志发现zrangebyscore指令很耗时,结合业务需求,在该指令中加上 limit 参数。
# 第二天推广
经过优化之后,MySQL和Redis的CPU利用率发生了明显的下降:
MySQL的CPU负载:
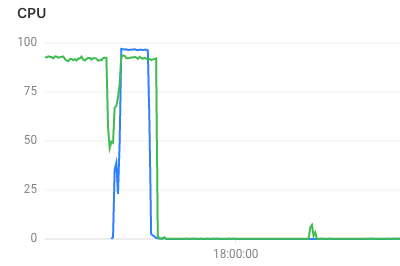
Redis的CPU负载:
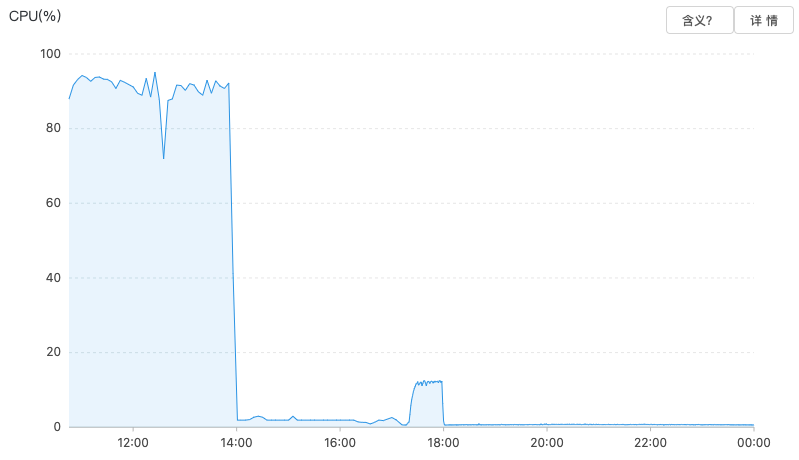
经过这些优化后,效果显著,轻松的抗住了客户A第二天的推广。客户表示满意,测试舒了口气,开发舒了口气,运维舒了口气,空气变得活泼了,故事到这里也就结束了。
# 异史氏曰
0.按照客户需求来做,不要侥幸。
1.不管是大项目还是小项目,在开发时应该尽量规范,比如多遵守下前辈总结的MySQL经验。
2.压测版本要一致,不要为了方便压测搞些特殊版本。
3.在大并发的场景下,流量是瞬间打上来的,给你调整配置的时间很短,如果你的配置顶不住,那么一瞬间就会奔溃。所以先按压测配置的双倍或多倍来扩容好服务器,数据库等配置,可以上线后看使用情况再来缩减配置。