# 粗浅地谈下为什么epoll好过select
在I/O多路复用中主要有两个模式select,epoll,说道它们的优劣时,都会说epoll好过select,但为什么好呢?我尝试粗浅地来说下原因,起到一个启发的作用,如有错误的地方请指正。 先啰嗦下I/O多路复用:一个线程管理多个socket,理解起来还是有点抽象,可以看下这个图:
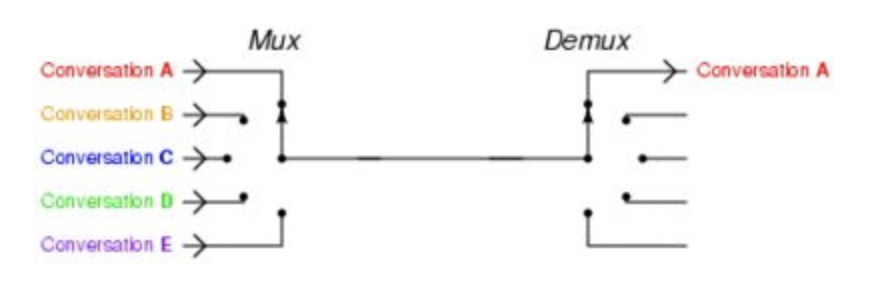
可以这样看:左边是连接的socket,中间是一个线程,右边是干活的代码。I/O多路复用其实就是这样通过拨开关的方式,来同时传输多个I/O流。左边谁有数据了,线程就把开关拨向谁,右边也拨向干活的代码。这样的过程就是I/O多路复用了。
# select
关键过程如下:
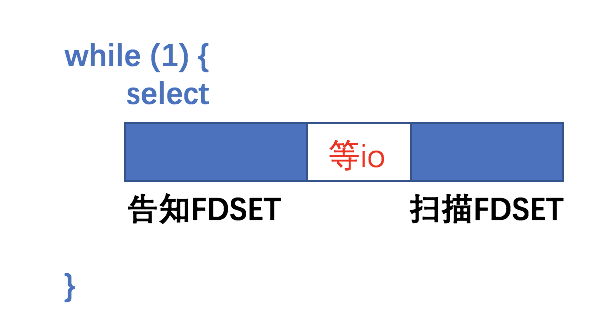
1.select把fd传入内核,这里花费的时间假设为O(n),n指的是fd的个数
2.等待io,这里的花费的时间假设为m
3.当有某个io请求时,select要扫描一遍fd,找出请求的fd,这里花费的时间假设为O(n),n指的是fd的个数
4.io结束后,又回到步骤1,重新把需要监听的fd传入内核
# epoll
epoll对select进行了改进,关键过程如下:
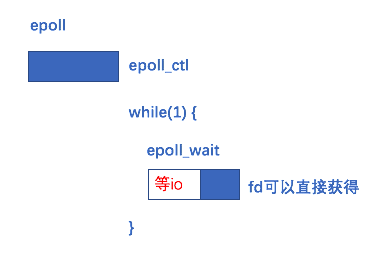
epoll多了几个api,其中有两个关键api: epoll_ctl 和 epoll_wait
epoll_ctl : 负责fd的管理,执行add,mod,del操作,执行add时,会向内核注册该fd的回调函数,内核检测到该fd可读可写时,内核调用该回调函数,回调函数将fd放到就绪链表
epoll_wait : 监控就绪链表,有fd时,返回到用户态
看下整个过程:
1.epoll_ctl初始化fd,这里花费的时间为O(n)
2.进入while死循环,执行epoll_wait
3.等待io,这里的花费的时间假设为m
4.当有某个io请求时,内核通过回调函数,将对应的fd直接放到就绪链表,epoll_wait检测到就绪列表的fd,将该fd返回用户态,这里花费的时间假设为1
# 总结
在select模式中,一次io需要时间为O(n) + m + O(n),如果有N次io请求,则需要的时间为:
N(O(n) + m + O(n))*。
在epoll模式中,一次io需要时间为O(n) + m +1,如果有N次io请求,则需要的时间为:
O(n) + N( m + 1)*。
通过这样粗浅地计算,可以看出epoll是明显优于select的,它只需要花费一次初始化fd的时间,之后fd由epoll_ctl接管,epoll_wait只负责监听。而select则每次都需要重新遍历fd,并且要遍历两次,一次用于扫描fd,一次用于找出需要用到的fd,整个时间复杂度是远远高于epoll,所以现在的高并发程序基本都用epoll,比如nginx。